
Blog
Attempt to improve item recommendation accuracy using Item2vec
Hi! I’m ML_Bear, an ML Engineer on Mercari’s Recommendation Team.
I’m in charge of improving the recommendation components displayed on the Mercari home page and elsewhere. Today I’m going to show you examples of how I improved the recommendation logic by using Mercari’s massive amount of log data and the metadata assigned to items sold on the Mercari app by users. (More details on the metadata below.)
Item Metadata
To improve the item search experience for users, Mercari assigns various kinds of metadata to the items on the app. For example, metadata for apparel includes color and the fabric’s texture, while for home appliances it contains model numbers. The different kinds of data that indicate an item’s traits is what we call metadata.
I’d like to take a look right now at the metadata we assign to books and manga (what I’ll refer to as “title data” below).
In the Mercari app, metadata is assigned to books and manga to show what series each item belongs to. For example, "Kingdom Vol. 1," "Kingdom Vol. 2," "Kingdom Vol. 25-50," and "Complete set of Kingdom" get the same "Kingdom" title data.
At Mercari, we also record all logs of items viewed by users.
So, I tested a way I thought we could improve book and manga recommendations to match user interests by reconciling those logs and title data while using the Item2Vec recommendation technique.
Using Item2Vec
Word2Vec1 is one well-known technique for natural language processing.It is a method that proposes words can be processed in a variety of ways by vectorizing them. Although it’s a fairly old technology, it is highly versatile, so it’s used in many kinds of research and in machine learning competitions.
Item2Vec2 is a way to apply that technique to item recommendations.
Implementation and training are relatively simple, and it’s a very easy way to produce accuracy. That’s why other companies have also shared use cases. It’s difficult to use if there aren’t many user logs, but personally, I think it’s highly suited to a service like Mercari that has a massive number of users and an enormous number of logs collected on a daily basis.
I created a recommendation logic with the following method.
-
Derive the similarity and relationship of each item. (With Python, process monthly by using data from N past months.)
a. Extract users who viewed book or manga items over the past N months.
b. Collect users’ item browsing histories over the past N months.
c. Extract arrays of titles viewed by session.
d. Regard title arrays as sentences and each title as a word, then derive title vectors with Item2Vec.
e. Use title vectors to derive relationships between titles (cos similarity).
f. Store data on relationship between titles in BigQuery. -
Generate recommendations for users. (With BigQuery, process hourly by using data from N past hours.)
a. Extract the history of items browsed by the user over the past N hours that are also tied to title data.
b. Derive "titles similar to item titles the user has viewed."
c. Store the data derived in the preceding step as "list of titles to recommend to users" in Bigtable.
d. If there is a title list to recommend in Bigtable when a user visits the home page, search for those titles and display them in the recommended item list.
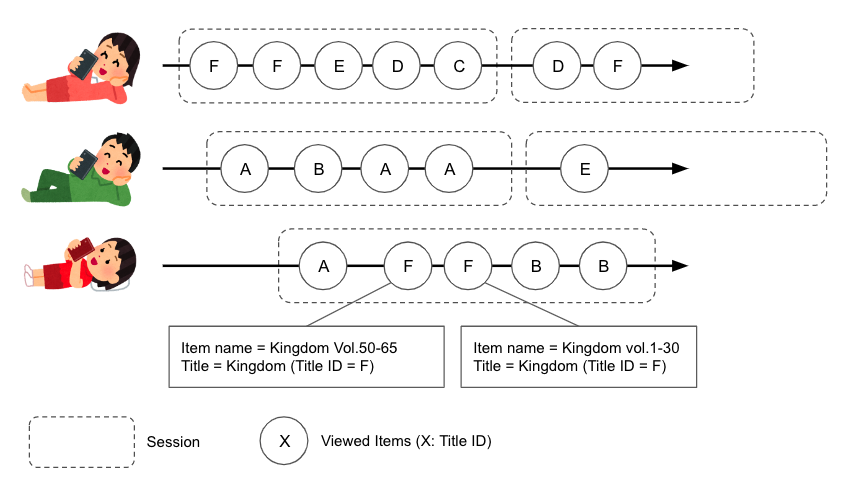
Fig1. Concept diagram for separating titles by sessions in item browsing logs
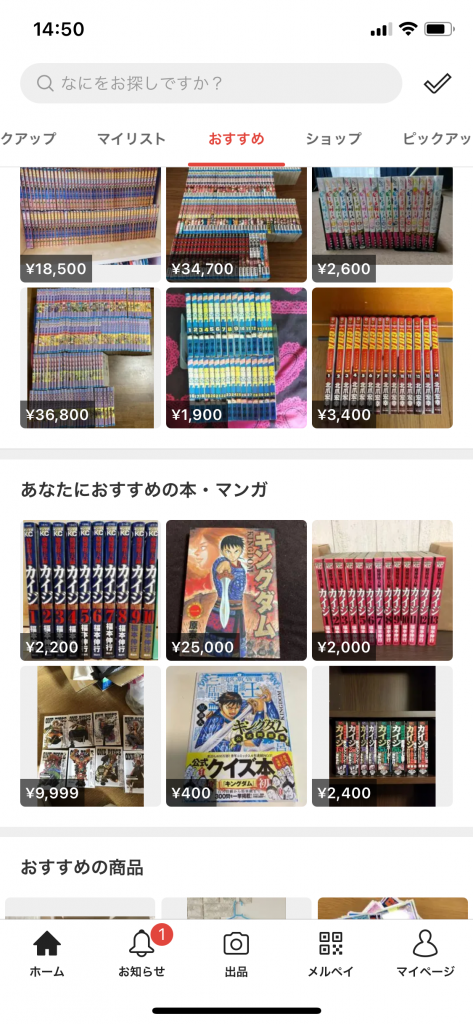
Fig2. The new recommendation section"Recommended Books & Manga for You"
I won’t discuss details about the system when it generates recommendation data or displays it in the app, but below is an overview (everything is processed on GCP)
- Process most data concerning item viewing logs with BigQuery (BigQuery makes it easy to process hundreds of millions of lines of log data.)
- Use Gensim on Colab to process Item2Vec calculations.
- For the data pipeline, use Cloud Compower (Airflow) to execute hourly and monthly data processing.
- Use Bigtable for the data store in the production environment.
Item2Vec Results
I’d like to show you some of the results from calculating with Item2Vec.
Below are the results from the most_similar function in the model I calculated with Gensim. (The number indicates the degree of similarity.)
Titles similar to the manga "Dragon Zakura"
1[('Dragon Zakura 2 17', 0.8193),
2 ('Angel Bank: Dragon Zakura Gaiden', 0.6674),
3 ('Let's Go to University of Tokyo: Dragon Zakura Official Guidebook', 0.628),
4 ('7 Skills from Dragon Zakura for Parents to Bring Out the Ability for Kids to Pass the University of Tokyo Entrance Exam: Longshan High School “Parent Skills” Special...', 0.5366),
5 ('Dragon Zakura Official Supplementary Reader, Age 16 Textbook 2, Where Do Study and Work Connect?', 0.5265),
6 (Gin no Anchor: Naitei Ukeoi Manga', 0.5145),
7 ('The Great War of Archimedes', 0.5118),
8 ('Bucho Shima Kosaku: Bilingual Edition', 0.5098),
9 ('Investor Z Complete', 0.5034),
10 (' Dragon Zakura Official Supplementary Reader, Age 16 Textbook, Why Study? What to Study?', 0.4913),
11...Dragon Zakura is a Japanese manga series written and illustrated by Norifusa Mita.
It tells the story of high school students studying to enter the University of Tokyo.
Supplementary readers for entrance exams are mixed in with Norifusa Mita’s works. I found this unexpected result very interesting.
Titles similar to the manga "Shoujiki Fudousan"
1[('24 Pieces of Divine Knowledge for Beating Real Estate Companies', 0.5547),
2 ('Stand Out at All Stages, From Novice to Veteran: The Most Powerful Real Estate Investing Textbook for Investors 1...', 0.493),
3 ('Kurosagi', 0.4731),
4 ('The Easiest Real Estate Investing Textbook in the World, 1st-Year Students: Perfect for Beginning Again', 0.4692),
5 ('Rumored Secret Drugs in Industry: Big Real Estate Techniques', 0.4675),
6 ('Souzoku Tantei', 0.4628),
7 ('The Future of Real Estate: Prepare for the Big Housing Turnover', 0.4405),
8 ('Worst Properties of the Year', 0.4351),
9 ('Real Estate Investing Don'ts', 0.4313),
10 ('Monkey Peak', 0.4291),
11...This is the story of a real estate agent who can’t tell a lie. The list includes "Kurosagi," which Takeshi Natsuhara (the original writer of "Shoujiki Fudousan") worked on. There is indeed a strong connection because the original writer is the same. It’s also interesting that the list includes regular real estate books among the manga.
By the way, I only just now learned about the manga "Souzoku Tantei" from writing this tech blog, so I took a break from writing, bought the digital edition, and gave it a read. It’s pretty good. It certainly feels similar to "Shoujiki Fudousan."
Titles similar to the novel "Clouds Above the Hill" by Ryotaro Shiba
2 ('Yo ni Sumu Hibi Complete', 0.7067),
3 ('Natsukusa no Fu Vol. 1 & 2', 0.6681),
4 ('Owl's Castle', 0.6624),
5 ('When the Last Sword Is Drawn Vol. 1 & 2', 0.6594),
6 ('Kashin Vol. 1-3', 0.653),
7 ('Sekigahara Vol. 1 & 2', 0.6471),
8 ('Oda Nobunaga', 0.647),
9 ('Komyo ga Tsuji', 0.6468),
10 ('The Last Shogun: The Life of Tokugawa Yoshinobu', 0.6324),
11...There are lots of works by Ryotaro Shiba.
Titles similar to the novel "Downtown Rocket" by Jun Ikeido
1[('Downtown Rocket: Ghost Yata Glass', 0.9246),
2 ('Downtown Rocket: Yata Glass Ghost', 0.9115),
3 ('Stock Price Crash', 0.8829),
4 ('Bank Manager Special Assignment, New Edition', 0.8819),
5 ('Hanasaki Mai Speaks Out', 0.8758),
6 ('Bitter Enemy', 0.8756),
7 ('Scandal, New Edition', 0.8702),
8 ('Bones of Steel', 0.8686),
9 ('Financial Detective', 0.8614),
10 ('Ginko Shiokinin', 0.8589),
11...This list also has many works by the author, in this case Jun Ikeido. Mercari users who search for novels might view many different works by the same writer.
Recommendation Logic A/B Testing
After completing Item2Vec, I ran A/B testing (also cleverly named: Book2Vec).
At Mercari, it’s a big part of our culture to quantitatively assess improvements with A/B testing. Team member yaginuuun released materials about our attempts to standardize A/B testing, so check those out. (Slides * This slide is in Japanese only)
In conclusion, it produced good results (though I can’t share the exact numbers) and the recommendation logic I made was adopted. I’m diligently developing it so pages in addition to the home page can use it too.
The joy I received from having the logic I created and implemented run on a service used by tens of millions of people is the best part about working as a Mercari engineer.
We’re Hiring!
In addition to metadata for books and manga, we intend to improve the recommendation logic we use for the massive amount of other data at Mercari.
As regular users of the Mercari app may be aware, the Mercari recommendation logic still has lots we can do with it and plenty of room for improvement.
The fact is, because of the massive number of visitors our site gets, a complex logic poses challenges because we can’t use it in the actual environment. On the other hand, however, if we have just one that works, then it will have extensive economic value. I want to keep on working out ways for users to find the items that are right for them.
If you’re interested in this work, I’d be happy to hear from you, as would my Mercari colleagues, so feel free to contact us. See ya!
Software Engineer, Machine Learning & Search – Mercari
References
[1] Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In Proceedings of NIPS 2013 (pp. 3111-3119).
[2] Oren Barkan and Noam Koenigstein. 2016. Item2vec: Neural item embedding for collaborative filtering. arXiv preprint arXiv:1603.04259.