
Blog
Improving Item Recommendation Accuracy Using Collaborative Filtering and Vector Search Engine
Hello, I am ML_Bear, an ML Engineer in the Mercari Recommend Team. In a previous article [1], I talked about improving Mercari’s home screen recommendations using item2vec and item metadata. This time, I will talk about improving recommendations on the item details screen. An example of the item details screen can be seen in figure 1. This screen is displayed to the user every time they want to see a detailed description of an item, which makes it a natural touch point to recommend similar items.
To make these improvements, we did the following:
- Implemented a vector search-based recommendation algorithm in one of Japan’s largest EC services, significantly improving recommendation accuracy.
- Successfully utilized user browsing history by constructing a recommendation algorithm using collaborative filtering and NN, avoiding the cold start problem.
- Accelerated extensive behavior user-browsing-log calculations using the Python implicit library and GPU during collaborative filtering learning.
- Created a lightweight NN model, partially referencing solutions from Kaggle competitions.
- Ensured continuous improvement by conducting offline evaluations using user-browsing-log in modeling.
- Adopted the VertexAI Matching Engine for our vector search engine, enabling efficient vector searches with a small team.
- Actual A/B testing led to the discovery of important features overlooked during NN modeling. After the initial test failure, we quickly corrected it and completed a powerful recommendation model contributing to the actual business.
Next, Iwill talk about some of the challenges we faced.
Figure 1. Target of this story: "Recommended for those who are viewing this item" (この商品を見ている人におすすめ)

Utilizing a vector search engine in Mercari
As introduced in the article [2] written by wakanapo last year, Mercari Group is trying to improve recommendation accuracy using vector search engines. The previous article was about improving recommendations for Mercari Shops items, but in this article, I will introduce an attempt to improve recommendations for all items listed on Mercari.
We adopted the Vertex AI Matching Engine [3] (the Matching Engine) for the vector search engine. We chose it because other teams have already been using it (allowing us to reuse some of their code and their operational know-how), and because it can withstand high access loads, as we will discuss later.
Item recommendation using vector search engine
The item recommendation system we built this time recommends items using the following flow. I will explain the details later, but here’s the basic idea:
(The numbers in parentheses correspond to the system architecture overview.)
- Indexing
- Calculate the item vector by some method (i, ii, iii)
- Store the item vector in the following two GCP services (iv)
- Bigtable [4]: Save all item vectors
- Matching Engine: Save vectors of items for sale
- Recommendation
- When a user views an item (1), recommendations are made using the following flow.
- Retrieve the vector of the item being viewed from Bigtable (2, 3)
- Use Matching Engine to search for items for sale with similar vectors, using approximate nearest neighbor search. (4, 5)
- Display the search results of Matching Engine in "Recommended for those who are viewing this item" (この商品を見ている人におすすめ) (6)
- When a user views an item (1), recommendations are made using the following flow.
Figure 2. System Architecture Overview
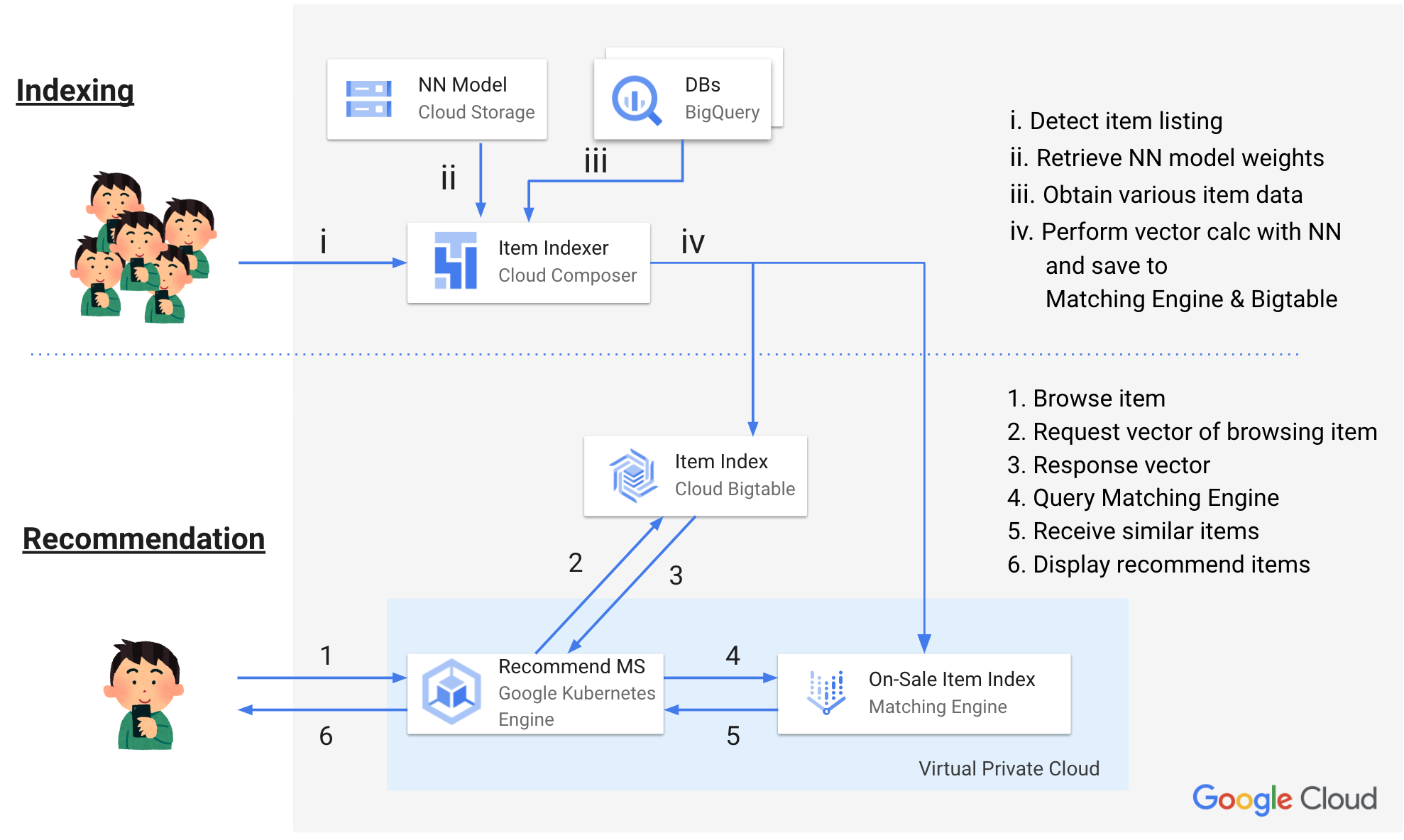
Initially, Matching Engine could only accept vectors as queries and return similar item IDs. This is why the Item index mapping in Bigtable (2, 3) is needed. Later improvements to Matching Engine removed the need for the mapping, as Matching Engine could now accept vector id directly.
We also adopted Streaming Update [5] for creating the Matching Engine index. I will not go into the details here, but with this method we can instantly reflect the addition of newly listed items to the index and the removal of sold-out items from the index. This was a very convenient feature for Mercari, where item inventory changes at an incredible pace.
The first A/B test targeting the toys category
The inventory on Mercari is huge with hundreds of millions of items for sale, and over 3 billion items listed in total [6]. Since the "Recommended for those who are viewing this item" part needs to be displayed even for sold-out items, we need to calculate vector embeddings for sold-out items as well.
To validate our hypothesis more quickly, we decided to focus on a specific subset of our inventory. If initial experiments work well, we could then expand it to the full item inventory. In this specific case, we decided to start with the toys category.
We selected the toys category first for the following reasons:
- The trends for items in this category changes very quickly, which results in our current recommendation logic not working very well. For example, when new characters were introduced in a TV show, unrelated items were being recommended when searching for the new characters. This was because we could not keep up with these additions, as well as new items related to them.
- The toys category contained several sub-categories with high sales volumes such as trading cards. We could expect improvements in recommendations to contribute to sales.
Utilizing collaborative filtering
For the modeling, I decided to use word2vec [7] for the baseline mode, as it was also used during work for improving Mercari Shops items. However, the metrics of offline evaluation (MRR: Mean Reciprocal Rank) did not perform well with word2vec when dealing with a very large number of items, and the recommended results did not look very good to our eyes either. Specifically, it seemed like subtle differences between items were being ignored as the number of items became large.
I also tried using a word2vec trained using our own dataset, but the accuracy did not improve as much as I expected. After some trial and error, I decided to use a more classical collaborative filtering.
Specifically, I used the Python “implicit” library [8] to calculate the factors of items from user browsing logs. The “implicit” library can accelerate calculations using GPUs, so it can complete calculations in a realistic time even if you put in billions of rows of data. In addition, it supports differential updates, so you can update to more sophisticated vectors as the item browsing history accumulates.
This library turned out to be extremely beneficial for Mercari, which has a huge amount of user log data and item data, but there were two problems.
- The handling of logs in the implicit library is very complicated
- Due to the constraints of the library, data must be handled with IDs starting from 0, and it requires a conversion table between implicit IDs and item IDs.
- Cold start problem
- Due to the nature of the marketplace app service, new items tend to attract more views. If the "Recommended for those who are viewing this item" does not work well for new items, it will negatively affect the user experience.
- (However, this is a problem with the collaborative filtering method itself, not just the implicit library.)
To solve these, just before the A/B test, we tested the following model changes.
- Calculate the vector (factor) of items with sufficient item browsing counts using collaborative filtering
- Train a neural network model (NN model) that reproduces the vector using item information such as title and item description
- Calculate the vector for all items in the toys category using the NN model and use it as the item vector.
I will skip over the details of the implementation of the NN model because it would make this post too long, but basically, I built a simple model with the following configuration. (We did not use heavy models such as BERT in the first test because we had to process tens of millions of items.)
Figure 3. NN Model Architecture (simplified)
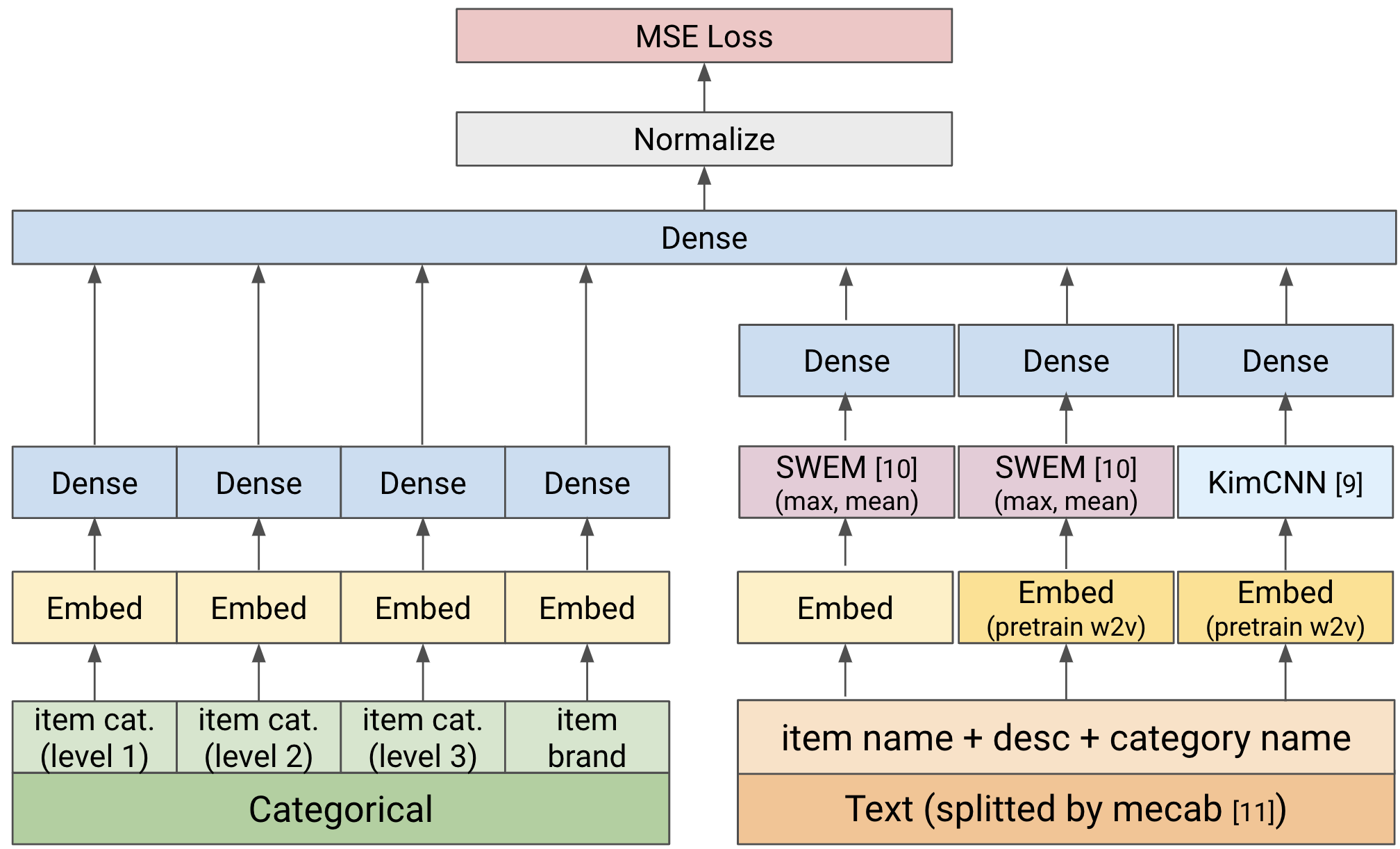
During string processing, we referred to some of the solutions of the Mercari Kaggle competition [13] (like processing the item title and category name together).
After a lot of work, I ended up having to approximate the collaborative filtering factors with a neural network. Other models such as two-tower models may have been more effective. We plan on trying this another time.
Recommending new items as much as possible
The first A/B test did not work out too well. Fortunately, we were able to quickly identify the cause of the failure and conduct a second A/B test, which was successful, so we were able to avoid further problems.
The reason for the failure was that we were recommending too many items that had been left unsold for a long time after being listed.
As I mentioned earlier, the item vectors were mainly generated using item information such as titles and descriptions, without considering when the items were listed (freshness). We later realized that when conducting offline evaluations, we only used data from specific periods, so the lack of consideration for freshness did not manifest itself as a problem during the modeling. As a result, we did not notice that we needed to consider the freshness of the items until the first A/B test.
After modifying the recommendation logic to consider the freshness of the items, the purchase rate of the recommended items improved significantly, leading to the overwhelming numerical improvements which I will talk about at the end of this article.
Other challenges
This was our first use of the Matching Engine at this scale. We encountered several issues while deploying in production. Some highlights:
- We were not able to find everything we needed in some of the documentation (how to use the SDK, how to configure the public endpoint, etc.), though the Google Cloud team was quick to answer our questions.
- There were occasional times when we could not get a GPU at all with GKE’s node auto-provisioning (NAP) [12], possibly due to a shortage of GPU resources in the Tokyo Region. In the end, we gave up on NAP and set up an instance to always keep a GPU. (I wonder if this is due to the rise of image generation AI…)
Improvement results: Item recommendation tap rate tripled
Now, as a result of the modeling described so far, we have achieved the ability to make the following recommendations. Previously, we were not effectively recommending related items when users were browsing items related to new characters. However, by adopting the approach presented this time, we were able to overcome this weakness.
Figure 4. Successfully making recommendations (The numbers in parentheses indicate the recommended order.)
Browsing item: ちいかわ ワクワクゆうえんち Pouch
Before improvement (many unrelated to “ちいかわ”):
[1] ハイキュー Art Coaster Bulk Pack
[2] 呪術廻戦0 TOHO-Lottery H-Prize Sticker...
[3] ちいかわ Mascot with Dialogue ハチワレ Prize Item
[4] 美少女戦士セーラームーンR S カードダス アマダ
[5] プロメア ガロ&リオ SGTver. Special Box PROMARE
[6] 宇宙戦艦ヤマト 2205 新たなる旅立ち Keychain Set
[7] Doraemon Wallet with Strap and Pass Case
[8] [New & Not for Sale] 日本食研 バンコ Plush Toy
[9] Pocket Monsters メイ EP-0137 Bath Towel Size...
[10]ちいかわワクワクゆうえんち Limited Edition Towel SetAfter improvement (recognizing “ちいかわ ワクワクゆうえんち”)
[1] ちいかわ ワクワクゆうえんち 2-Piece Set Pouch Jet Co...
[2] ちいかわ ワクワクゆうえんち Pouch
[3] ちいかわワクワクゆうえんち Limited Edition Towel Set
[4] Anonymous Delivery ちいかわワクワクゆうえんち Gacha Ax…
[5] ちいかわ ワクワクゆうえんち Mug Cup
[6] Anonymous Delivery Unopened New ちいかわ ワクワクゆうえんち Mascot...
[7] ちいかわ ワクワク ゆうえんち Side Plate
[8] ちいかわ ワクワクゆうえんち Mini Frame Art ハチワレ
[9] ちいかわ ワクワクゆうえんち Mascot Set
[10] ちいかわ ワクワクゆうえんち 2-Piece Set Pouch(For copyright reasons, I will not upload images here, but you can see the results yourself by looking up items on the app.)
As a result of the A/B test, we were able to achieve the following great results.
- The tap rate for items under "Recommended for people viewing this item" tripled
- Purchases from "Recommended for people viewing this item" increased by 20%
- As a result, the Mercari app’s overall sales increased significantly.
Of course, it’s great that the business metrics have improved, but more importantly, we were able to properly recommend items more strongly related to the items users are viewing, and we were proud of that as a team.
There’s still room for improvement
I had a lot of information to present, and the detailed explanations for each section ended up being very concise, but I hope this served as a helpful reference for you.
This time the model design itself was very simple, as it was the first test of vector search item recommendation for all of Mercari. We have not considered images yet, and we have not used advanced features of the Matching Engine (such as the Crowding Option [14] for diversity).
In addition, we have not yet applied this model to categories other than toys, so there is still room for improvement. We will continue to make improvements and evolve the service to be better.
Let me know if you have any opinions or impressions on Twitter or elsewhere.
See you again!
References
[1] Attempt to improve item recommendation accuracy using Item2vec | Mercari Engineering
[2] Vertex AI Matching Engineをつかった類似商品検索APIの開発 | メルカリエンジニアリング
[3] Vertex AI Matching Engine overview | Google Cloud
[4] Cloud Bigtable: HBase-compatible NoSQL database
[5] Update and rebuild an active index | Vertex AI | Google Cloud
[6] フリマアプリ「メルカリ」累計出品数が30億品を突破
[7] [1301.3781] Efficient Estimation of Word Representations in Vector Space
[8] GitHub – benfred/implicit: Fast Python Collaborative Filtering for Implicit Feedback Datasets
[9] [1408.5882] Convolutional Neural Networks for Sentence Classification
[10] [1805.09843] Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
[11] MeCab: Yet Another Part-of-Speech and Morphological Analyzer
[12] Mercari Golf: 0.3875 CV in 75 LOC, 1900 s | Kaggle
[13] Use node auto-provisioning | Google Kubernetes Engine(GKE)
[14] Update and rebuild an active index | Vertex AI | Google Cloud