
Blog
自己教師あり学習のナチュラルビュー
機械学習のためにラベルを作るのは大変な手間と時間がかかります。ラベル無しで機械学習モデルに学習させることができたら良いと思いませんか?自己教師あり学習ではそれができます。
私はAI/MLチームのポール・ウィロット(Paul Willot)です。私たちは、メルカリのデータを利用することでラベル無しで済むための実験を行いました。本稿では、その実験についてご紹介いたします。
それでは、始めましょう!
自己教師あり学習
自己教師あり学習(Self-Supervised Learning、略してSSL)は、外部の教師ラベルを必要としない学習方法です。その代わり、ラベルがプロキシタスクから生成されます。このタスクを解くには、後続の応用タスクに適用可能な表現を学習モデルに学ばせる必要があります。
もちろん難しいのは、そのプロキシタスクを定義することです!作成方法を説明する前に、そもそもSSLがなぜ便利なのかを見ていきましょう!
なぜ、SSLか?
要約すると、良いラベルを集めるのは大変ですが、生データは豊富にあるということです。SSLでは、大量のデータセットを使用して機械学習モデルを作成開始することができ、ほんの少しの高品質なサンプルを微調整するだけで済むのです。
具体的な例を挙げてみましょう。
メルカリに出品をする際、その商品をなるべく買い手が簡単に見つけられるように最適なカテゴリーを選ぶことができます。しかし、正しいカテゴリーを選ぶのは面倒です。
機械学習(ML)は、商品画像から適切なカテゴリーを即時に提案してくれます。この課題は、単純な分類問題として定義され、一般的な機械学習のタスクです。素晴らしいですね!
ただし、既存のカテゴリー、つまり現在あるラベルにはいくつか課題があります。とりわけ問題となるのが、クラスの不均衡、、ラベルノイズ(複数ある中から選ぶのが難しい)、曖昧性(商品によっては、適切なカテゴリーが複数あるため)です。また、他のタスクへの適用が難しいタスク特有の表現を学習モデルに学習させることも課題です。
これら課題は、そもそもラベルが必要であるから存在するのであり、その必要性がなければそれに越したことはないのです。そこで役立つのが自己教師あり学習です。
プロキシタスクの定義
多様なプロキシタスクがSSL用に作られてきました。例えば、ジグソーパズルを解く、画像回転を予測するなどです。
最近の最先端の方法は、ランダムに変換された画像をつかったプロキシタスクに注目しており、そのタスクは視覚的な変形にもかかわらず一貫した表現を取得することとして定義されています。
例えば、以下のゴールデンレトリーバーの画像ですが、変更が加えられた後も、変換された画像ひとつひとつ(ビューと呼ばれる)にその犬を認識できる断片が含まれています。

Augmented views
ただし、どの拡張データを使用するかを決めるのは簡単ではありません。学習モデルが、役に立つ表現を学習できる程度に難しくする必要がありますが、とはいえ難し過ぎても学習することができません。データ拡張によりデザインの選択肢が増え、正しいものを選択することが現在の研究課題となっています。
理想を言えば、実際に存在するビューを使用したいものです。

Natural views
幸いなことに、メルカリには数十億ものビューがあります!
商品を売る際、様々な角度から撮影した画像を投稿すると商品に対する買手の印象は良くなります。そのため、大半の出品物には複数のビューがあります。ごく自然な設定で商品の様々な側面を見せるために撮られた画像ということから、私たちは「ナチュラルビュー」と呼んでいます。
ここで留意すべきことは、ビューの違いは単にカメラのアングルが違うのでは?というだけではないことです。例えば、上の画像の靴は、箱の上で様々な角度に置かれています。これはベストです!ある特定の構図に縛られることのない共通の表現を学習モデルに学習できるのです。
ビューの組合せによっては、関連付けるのがより難しい場合もあります。例えば、別々に撮影されたある商品とそれを入れるための箱です。実際のところ、これは、比較的まれなことなので大した問題とはなりませんでした。
Contrastive learning
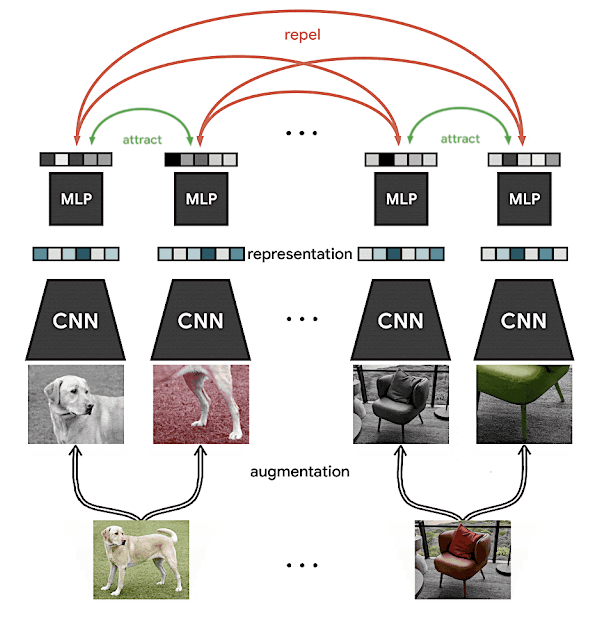
Contrastive learning on a pair of images (credit: SimCLR)
ところで、それらのビューがあればContrastive learningb>を通じて学習対象を定義することができます。つまり、同じビューはより似通った表現となり、異なるビューは似ていない表現となるb>ということです。上記の図で示す通り、同じ商品は、見た目が近いビューという表現になり、異なる商品は、見た目が違うビューという表現になるのです。
尚、「埋め込み」と「表現」は、意味上では同義として使用されており、両方ともSSL環境下では、1次元のスカラー×ベクトルを表します。
Contrastive learningは、シャムネットワークに関係する古いタイプの機械学習法ですが、この2年間、ImageNet のベンチマークで、教師あり学習との間にできた差を縮めてきている多くの方法と共に人気を取り戻してきています。このSimCLR ブログ記事は、この件に関して、さらに深く掘り下げて考察するのにちょうど良い記事です。
「Bootstrap Your Own Latent」という論文で紹介されてからというもの、最近では、モーメンタムをベースとした技法も見られるようになってきました。それらの技法は、ポジティブペアのみを使用することで実装を簡略化し、バッチサイズが大きくなるという問題を解消します。モーメンタム学習について理解するには、SimSiamに関する論文をお勧めします。
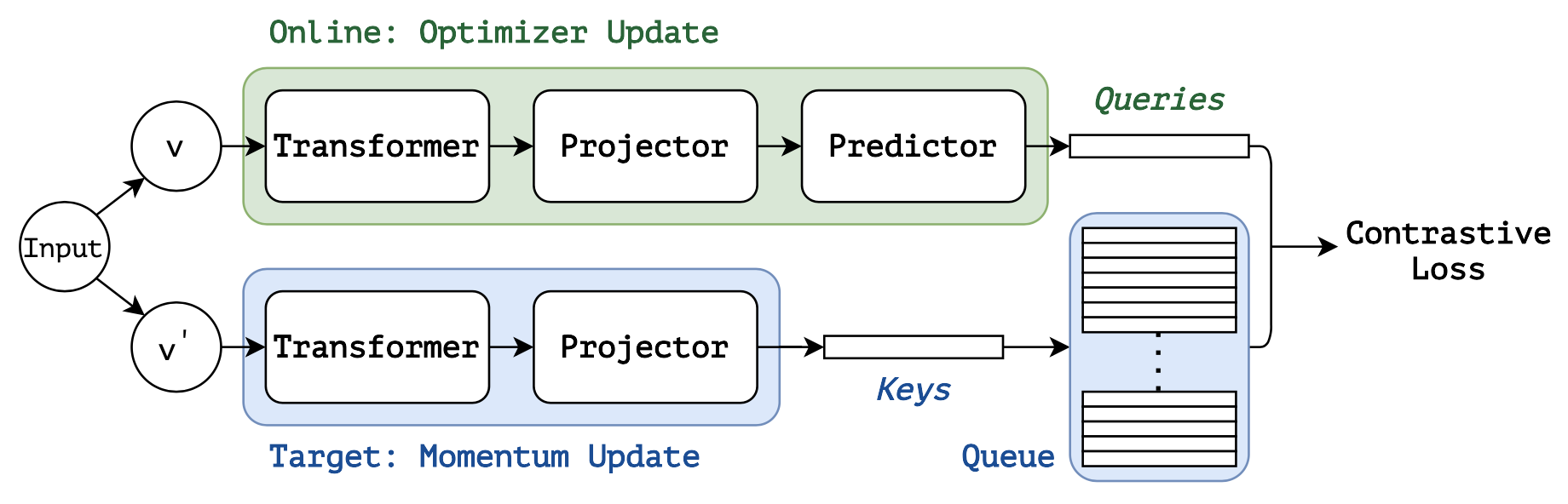
contrastive損失関数やモーメンタム学習のあるSSLは、MoBYという別名で知られています。 (credit: Self-Supervised Learning with Swin Transformers)
最新の研究では、この2つを結びつけたりもします。その良い例が、私たちが実験で使用したMoBYです。
これらの方法における重要なポイントは、複数ビューの対象に関する一貫した表現を獲得する学習モデルの作成が可能になるということです。
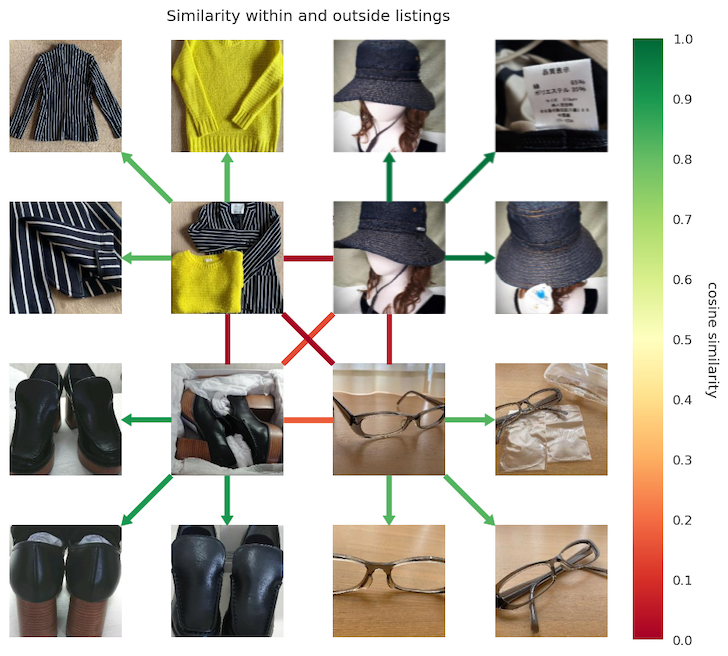
リスト内外のビューを表現する間の距離
各四分円は1つのリストで、最も内側のリンクはリスト間です
緑=類似、赤=非類似を表しています
上記の通り、私たちのデータセットでこのことを確認することができました。学習後、商品は構図が大きく変わっていようと、または細部が拡大表示されていようと、ことなった商品間よりもある一つの商品内においてのほうがより互いに似たものとなります。
今回の実験で、学習に関して役立った情報は以下の通りです。
- サイズの大きいデータセットは、いかなる非自明なタスクにも必要。何百万ものサンプルを考慮するべきである
- 学習については、事前学習済みの重みがあれば、GPUで数日、そうでなければ1~2週間かかる
- 大きな学習モデルのほうが学習させやすく、ResNet-50は、2021年の時点でもベースラインとしていまだ信頼性が高い
- 単純な方法は大いに役立つ。SimSiamから始めよう
- SSLは素晴らしいが、既にラベルがあるのであれば、それを使用するべきだ。より正確に早く学習させることができる
学習済み表現の使用
これらの画像から得られた表現を使用して、後続の応用タスクを開発するための方法がいくつかあります。
ラベルを使用して、ある特定の学習モデルを埋め込み後に学習させることができますが、入力スペースがより小さく単純なため、必要サンプル数は(生の画像と比較して)より少なくてすみます。
また、あるサンプルから最も近い表現を最近傍探索で見つけることで、そのサンプルの特性を推論することができます。その利点は、追加的な学習が必要なく、そのサンプルに最も近いものでさえあれば、構造が不十分であってもその特性を利用することができるということです。
私たちは、コサイン類似度を算出、(又は一対のサンプル間で直接相違を測定)することができましたが、メルカリの規模では、すぐに計算処理ができなくなります。代わりに、FAISSやScaNNのように、既存のデータベースを利用したベクトル類似性検索をし、わずか数ミリ秒で何百万ものサンプルを検索することができます。
結論
たとえラベルがなくても、手元にあるデータの既存構造を利用することで利便性の高い学習モデルに学習させることができます。
メルカリでは、価格の推定、不正出品の特定、顧客別プロフィール設定、エッジでの物体検出など、あらゆる場面で機械学習を利用しています。
コストのかかるラベルを使用せず、画像から直接、汎用性の高い表現を獲得することで、これら多様なタスクの処理がしやすくなります。
お読みいただき、ありがとうございました!