Blog
協調フィルタリングとベクトル検索エンジンを利用した商品推薦精度改善の試み
こんにちは、メルカリのレコメンドチームで ML Engineer をしている ML_Bear です。
以前の記事 [1] では、item2vecと商品メタデータを用いた、メルカリのホーム画面のレコメンド改善のお話をさせていただきました。今回は商品詳細画面でレコメンド改善を行ったお話をさせていただきます。商品詳細画面の例は図1の通りです。ユーザーはアイテムの詳細な説明を見たいときにこの画面に来訪するため、同様の商品を推薦する自然な接点として非常に重要です。
まず、私たちが商品詳細画面で行った改善の概要を示します。各部の詳細については次節以降で詳しく触れます。
- 日本有数の大規模ECサービスにおいてベクトル検索ベースの商品推薦アルゴリズムを実装し、推薦精度の大幅な改善を実現しました。
- 協調フィルタリングとニューラルネットワーク (以下、NN) を利用した商品推薦アルゴリズムを構築し、コールドスタート問題を回避しつつ、ユーザーの閲覧履歴を活用することに成功しました。
- 協調フィルタリングの学習の際にはPython implicitライブラリを活用し、GPUを利用して膨大な行動ログの計算を高速化しました。
- NNのモデリングではKaggleコンペティションのsolutionなども一部参考にしつつ、極めて軽量なモデルを作成しました。
- モデリングではアクセスログを活用したオフライン評価を行うことで、改善が常に正しい方向へ向かうように工夫しました。
- ベクトル検索エンジンにはVertexAI Matching Engineを採用して、少ない工数でベクトル検索を実現しました。
- VertexAI Matching Engineは本番運用の高負荷にも十分耐えうるものであり、テスト実行後、迅速に本番適用へ移行することが可能でした。
- 実際のABテストでモデリング時に見逃していた重要な特徴量も発見することができました。初回のテストの失敗後、それを迅速に修正し、実ビジネスに貢献する強力な推薦モデルの構築に成功しました。
図1. 今回のお話の対象「この商品を見ている人におすすめ」

メルカリにおけるベクトル検索エンジンの活用
昨年、wakanapo が書いた記事 [2] でも紹介した通り、メルカリグループではベクトル検索エンジンを活用したレコメンド精度改善にトライしています。以前の記事はメルカリShopsの商品に限定した改善の試みのお話でしたが、今回の私の記事では、メルカリに出品されている全ての商品を対象とした改善の試みをご紹介します。
ベクトル検索エンジンは wakanapo の記事と同様に、Vertex AI Matching Engine [3] (以下、Matching Engine と表記) を採用しました。既に社内での導入事例があるためコードベースや運用ノウハウが流用できること、また、後述の通り高いアクセス負荷にも耐えられることから採用しました。
ベクトル検索エンジンを利用した商品推薦
今回構築した商品レコメンドシステムは以下のような流れで商品を推薦します。(詳細については以降のパートで詳しく説明します)
(括弧内の数字はシステムアーキテクチャ概略図に対応)
- Indexing
- “何らかの方法” で商品のベクトルを計算する (i, ii, iii)
- 商品のベクトルを以下2つのGCPサービスに格納する (iv)
- Bigtable [4]: 全ての商品のベクトルを保存する
- Matching Engine: 販売中の商品のベクトルを保存する
- Recommendation
- ユーザーが商品を閲覧した際 (1) に、以下の流れで推薦を行う。
- Bigtable から閲覧中の商品のベクトルを取得する (2, 3)
- Matching Engine を用いて、そのベクトルと似たベクトルを持つ、販売中の商品を近似近傍探索する。(4, 5)
- Matching Engine の検索結果を「この商品を見ている人におすすめ」に表示する (6)
- ユーザーが商品を閲覧した際 (1) に、以下の流れで推薦を行う。
図2. システムアーキテクチャ概略図

ちなみに、当初、Matching Engine はベクトルをクエリとして受け付けて、それに対して類似商品のIDを返す、という動作しかできなかったため、Bigtableを必要とする構成になっています。現在は Matching Engine のアップデートにより、(ベクトルの代わりに) 商品IDを投げると類似商品を返してくれるようになったため、Bigtableを不要にすることも可能です。
また、Matching Engineのインデックス作成にはStreaming Update [5]というものを採用しました。詳細は省略しますが、この方式でインデックスを作成しておくと、新たに出品された商品のインデックスへの追加や、売り切れてしまった商品のインデックスからの削除を瞬時にインデックスへ反映することができます。ものすごい勢いで商品の在庫が入れ替わっていくメルカリでは非常に便利な機能でした。
初回のABテストはおもちゃカテゴリを対象
メルカリは販売中の商品だけで数億点、過去全てを累計すると30億点以上[6]の商品が出品されています。「この商品を見ている人におすすめ」 のレコメンドパーツは売り切れた商品にも表示する必要があるため、売り切れた商品にもベクトルの計算が必要です。
仮説の迅速な検証のため、初回のABテストでは一部の商品のみを対象としました。具体的には、まずおもちゃカテゴリを初回の対象カテゴリとして選定し、そのテストが成功した後に、より多くのカテゴリに展開することとしました。参考までに、おもちゃカテゴリを選定した理由は以下の通りです。
- 商品の流行り廃りがあまりにも早いため、現在のレコメンドのロジックがうまく機能していない。具体的には新商品や新キャラクターに全く対応が追いついておらず、新しく登場した人気キャラクターの商品に対して、全く関係ない商品が表示されたりする。
- トレーディングカードをはじめとして売上の大きいカテゴリが複数存在しており、推薦の改善によって、売り上げへの貢献が期待できる。
協調フィルタリングの活用
メルカリShopsの改善では word2vec [7] を活用していたため、今回、私がモデリングを行った際にもword2vecを利用してベースラインモデルを構築しました。しかし非常に多くの商品を扱う際には、word2vecではオフライン評価のメトリクス (MRR: Mean Reciprocal Rank) が伸び悩み、また、目視での推薦結果もあまり満足のいくものではありませんでした。具体的には、商品数が非常に多くなった場合は商品の細かな違いを区別できていないような挙動でした。
一般に配布されている学習済みword2vec以外にも、自社のデータセットで word2vec を学習してみたりもしましたが、思ったほど精度は伸びなかったため、試行錯誤の結果、古典的な協調フィルタリングを利用することにしました。
具体的には、Python の implicit ライブラリ [8] を利用し、ユーザーの閲覧ログから商品の factor を計算しました。 implicit ライブラリはGPUを使って計算を高速化できるため、数億行のデータを突っ込んでも現実的な時間で計算を完了してくれます。また、差分更新にも対応しており、商品の閲覧履歴が溜まるとより精緻なベクトルに更新していくことが可能です。
莫大なユーザーログデータと商品データ数を有するメルカリにとって、このライブラリの存在は非常にありがたいのですが、以下2点の課題がありました。
- implicit ライブラリのログの取り回しが非常に煩雑
- ライブラリの制約から0始まりのidでデータを扱う必要があり、implicit id と商品idの変換テーブルが必要 (データパイプラインが複雑になって辛い)
- コールドスタート問題
- フリマアプリというサービスの特性上、新しいものに閲覧が集中する。新しい商品では「この商品を見ている人におすすめ」があまり機能しない、というのはユーザー体験の毀損につながってしまう。
- (ただこれは協調フィルタリングという手法そのものの問題なのでimplicit単体の問題ではない)
よって、ABテストを行う直前に、以下のようなモデルに変更を行ってテストしました。
- 十分な商品閲覧数をもつ商品に対して協調フィルタリングでベクトル (factor) を計算する
- タイトル、商品説明文などの商品情報を利用してそのベクトルを再現するNNモデルを学習する
- おもちゃカテゴリの全ての商品に対してNNモデルでベクトルを計算し、それを商品のベクトルとして利用する。
NNモデルの実装詳細まで書くと長くなってしまうので詳細は省略しますが、以下のような構成のシンプルなモデルを組みました。(数千万商品を処理する必要があるため、初回のテストではBERTなどの重いモデルは利用しませんでした)
図3. NNモデルアーキテクチャ (一部簡略化)
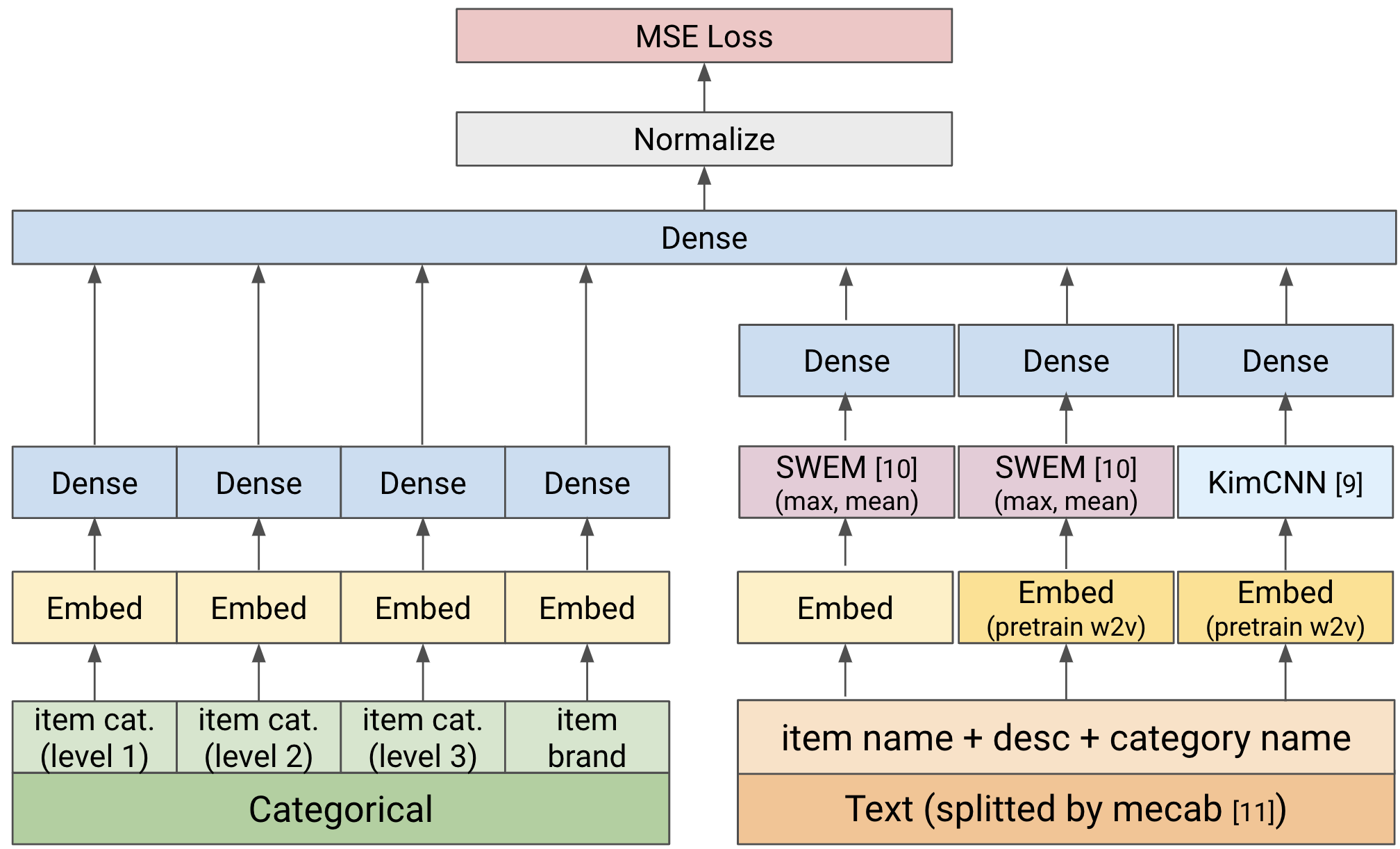
テキスト処理において商品タイトルにカテゴリー情報の文字列を足すと言った点は、Kaggleのメルカリコンペ[12] の解法を参照しました。
紆余曲折あって協調フィルタリングのfactorをNNで近似するという結構無理やりな問題設定になってしまったので、別の機会にtwo-tower モデルなどのより効果的と思われるモデルのテストを実施したいと思っています。
なるべく新しい商品を推薦する
実は今回のABテストは一度失敗しました。幸いにも、データ分析の結果すぐに敗因が特定できたので2回目のABテストを実施し、それが成功したのでことなきを得ました。
失敗した原因は「出品から長い時間売れ残って放置されている商品をたくさん推薦してしまっていた」ということでした。
前述の通り、今回の商品ベクトルは主に商品情報 (タイトル・説明文など) を利用してベクトルを生成していましたが、商品がいつごろ出品されたものかということ(新鮮さ)の考慮はしていませんでした。後からわかったことですが、オフライン評価を行う際には、特定の時期のデータのみを利用していたため、新鮮さを考慮しないことがモデリングの問題にならなかったようです。そのため、初回のABテストを行うまで、商品の新鮮さを考慮する必要性に気づけませんでした。
商品の新鮮さを考慮するように推薦ロジックを修正した結果、推薦された商品の購買率が一気に向上し、記事末尾で述べる圧倒的な数値改善に繋げることができました。
その他の苦労した点
これは私たちがMatching Engineを大規模に利用した初めての事例でした。本番環境への適用の際にいくつか問題があったので、以下に箇条書きで列挙しておきます。
- Google Cloudのサポートチームがチケットで質問に気軽に対応してくれましたが、Matching Engineのドキュメントにはまだまだ不足している点が多かったです。(SDKの利用方法、Public Endpointの構成方法など。)
- Tokyo Region の GPU リソースが不足しているためか、GKEのノード自動プロビジョニング(NAP) [13] で全然GPUを掴めないタイミングが稀によくあった。結局、NAPを諦めてインスタンスを1個立ててGPUを常に確保した。(画像生成AIの隆盛の影響だったりするのでしょうか…。)
改善結果 – 商品推薦タップ率が3倍に
さて、ここまで書いてきたモデリングの結果、以下のような推薦を行えるようになりました。ユーザーが新しいキャラクターに関連する商品を閲覧している場合、関連する商品をうまく推薦できていなかったのですが、今回の手法を採用することで、その弱点を克服することができました。
図4. うまく推薦を行えるようになりました ([]内の数字は推薦順位)
閲覧中の商品: ちいかわ ワクワクゆうえんち ポーチ
改善前の推薦商品リスト (ちいかわと全然関係ないものも多い)
[1] ハイキュー アートコースター まとめ売り
[2] 呪術廻戦0 TOHOくじ H賞 ステッカー ジッパー...
[3] ちいかわ セリフ付きマスコット ハチワレ プライズ品
[4] 美少女戦士セーラームーンR S カードダス アマダ
[5] プロメア ガロ&リオ SGTver. Special Box PROMARE
[6] 宇宙戦艦ヤマト 2205 新たなる旅立ち キーホルダー まとめて
[7] ドラえもんストラップ付 財布 パスケース
[8] 【新品・非売品】日本食研 バンコ ぬいぐるみ
[9] ポケットモンスター メイ EP-0137バスタオル サイズ...
[10]ちいかわワクワクゆうえんち 限定 タオルセット改善後の推薦商品リスト (“ちいかわ ワクワクゆうえんち”を認識している)
[1] ちいかわ ワクワクゆうえんち 2個セット ポーチ ジェットコ...
[2] ちいかわ ワクワクゆうえんち ポーチ
[3] ちいかわワクワクゆうえんち 限定 タオルセット
[4] 匿名配送 ちいかわワクワクゆうえんち ガチャアクスタ3種
[5] ちいかわ ワクワクゆうえんち マグカップ
[6] 匿名配送 新品未開封 ちいかわ ワクワクゆうえんちマコット...
[7] ちいかわ ワクワク ゆうえんち 中皿
[8] ちいかわ ワクワクゆうえんち ミニフレームアート ハチワレ
[9] ちいかわ ワクワクゆうえんち マスコット セット売り
[10] ちいかわ ワクワクゆうえんち 2個セットポーチ(この記事においては著作権に配慮し、推薦される商品の商品名の羅列のみとしております、実際にお手元のアプリで確認してみてください。)
ABテストを行った結果、以下のような驚くべき結果を叩き出すことができました。
- 「この商品を見ている人におすすめ」の商品タップ率が3倍
- 「この商品を見ている人におすすめ」からの購入が20%増加
- 上記の結果、メルカリアプリ全体の売り上げが大幅に向上
経営に関するメトリクスが向上したことは当然嬉しいのですが、何よりも、ちゃんとユーザーが閲覧している商品に対して、関係性の深い商品をきちんと提案できるようになったこと、また、それをチームとして誇りに思えたことが何よりも嬉しかったです。
まだまだ改善の余地あり
ご紹介したい内容が多く、各部の詳細は非常に簡潔な説明となってしまいましたが、参考になりましたでしょうか?
今回はメルカリ全体でのベクトル検索商品推薦の初回テストということもあり、モデルの設計自体は非常にシンプルなものでした。まだ画像を考慮に入れていなかったり、Matching Engineの高度な機能 (多様性を出すための Crowding Option [14] という機能など) もまだ使っていません。
また、おもちゃカテゴリ以外では今回の施策の適用もしておらず、まだまだ改善の余地があります。今後も改善を繰り返して、より良いサービスへと進化させていきたいと思っています。
ご意見ご感想などあれば Twitter などで聞かせてください。
それではまたお会いしましょう。
References
[1] Item2vecを用いた商品レコメンド精度改善の試み | メルカリエンジニアリング
[2] Vertex AI Matching Engineをつかった類似商品検索APIの開発 | メルカリエンジニアリング
[3] Vertex AI Matching Engine overview | Google Cloud
[4] Cloud Bigtable: HBase 対応の NoSQL データベース
[5] Update and rebuild an active index | Vertex AI | Google Cloud
[6] フリマアプリ「メルカリ」累計出品数が30億品を突破
[7] [1301.3781] Efficient Estimation of Word Representations in Vector Space
[8] GitHub – benfred/implicit: Fast Python Collaborative Filtering for Implicit Feedback Datasets
[9] [1408.5882] Convolutional Neural Networks for Sentence Classification
[10] [1805.09843] Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
[11] MeCab: Yet Another Part-of-Speech and Morphological Analyzer
[12] Mercari Golf: 0.3875 CV in 75 LOC, 1900 s | Kaggle
[13] Use node auto-provisioning | Google Kubernetes Engine(GKE)
[14] Update and rebuild an active index | Vertex AI | Google Cloud